<onWebFocus />
Knowledge is only real when shared.
Hasura
October 4, 2021
Automatically generated GraphQL backend.
As more and more logic is put into the Frontend where computation resources are plenty and free for the provider of parts on the server. Hasura takes this approach much further and allows a Frontend developer to quickly set up a GraphQL backend by simply defining the database tables and their columns using a graphical interface.
The Magic
The tool will then inspect the tables and generate an extensive GraphQL interface to create, read update and remove data. Built in are also various helper properties so only the required data is sent. These properties are very similar to the ones used for regular database queries in the backend. This completely removes the middle step where the developer manually has to write backend code to get only the appropriate data from the database and also provide an interface.
Why GraphQL
GraphQL technology can be leveraged to only retrieve the fields you actually need. This can be used to reduce the bandwidth required to get the data while still having extensive models in the backend. This is especially relevant when performing nested queries and has been the reason why GraphQL has been created in the first place.
Even though property date would be available in this case we only need the id and the name of the books. The date is irrelevant.
The following query will only return books where the name matches a certain Regular Expression.
Logic
Of course the backend usually consists of more than just reading and writing data from a database. Also, the backend has access to resources that clients should not. Hasura offers various techniques to ensure these types of logic still have their place.
The most familiar one is Actions or webhooks that execute when certain queries are run. The effort to create an action is comparable to setting up a mini-backend possibly with full access to the hasura backend through theX-Hasura-Admin-Secret. Needless to say Actions are to be avoided due to the effort required which hasura tries to avoid in the first place.
Much simpler are Permissions which can be set per table to make sure certain users only have access to data they should have access to. Permissions are based on Roles. Queries with the X-Hasura-Admin-Secret are automatically assigned the admin role and usually have access to all data. Obviously, this header should never be passed to the client. Clients can read data depending on the role they are assigned.
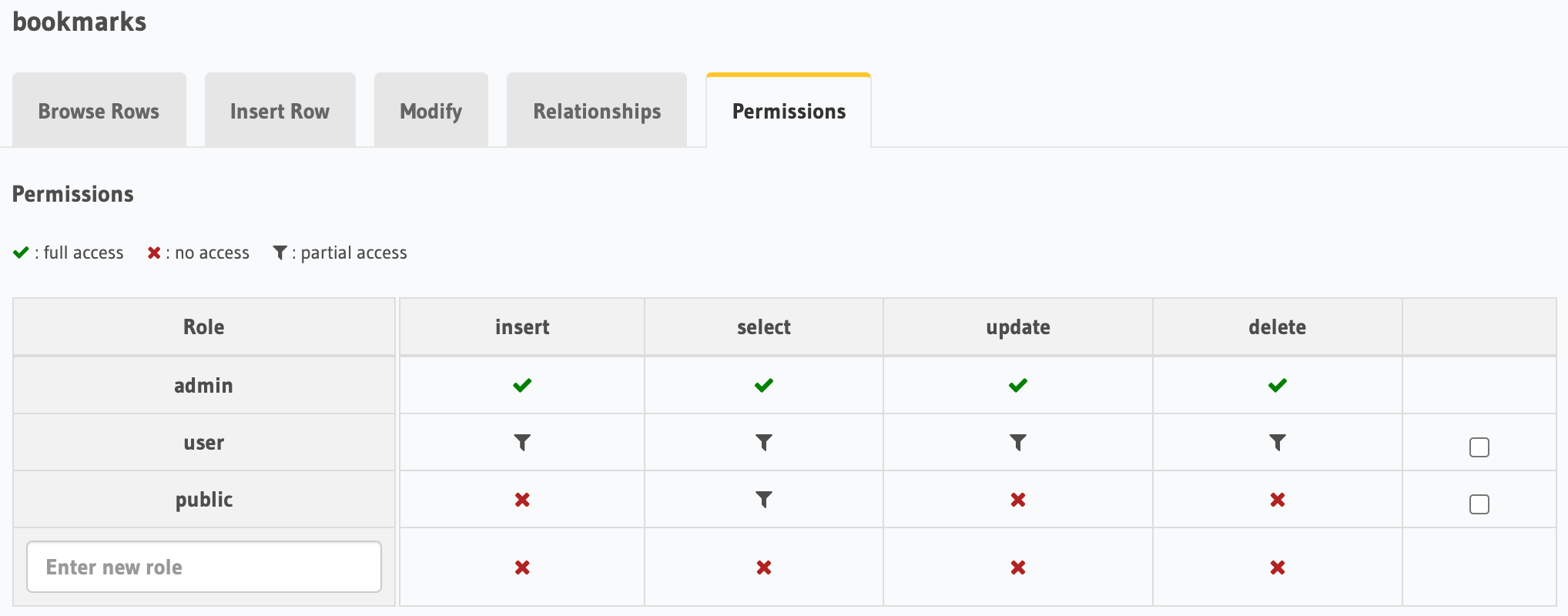
Access is based on role and operation. Permissions can be given, refused or based on filters. Filters are espectially interesting as they can be very dynamic based on the headers and the data in the table. For example, a custom check like { "views": { "_gt": 1000 }} would make sure that a certain role would filter out all entries with less than 1000 views.
In many cases you want to make sure that a user only has access to its own entries in a table. This can be achieved by adding a user id to each entry which them needs to be passed as a header with the query. Such a filter looks like { "user_id": { "_eq": "X-Hasura-User-Id" }}.
For safety reasons the client cannot directly set its available headers and roles. For this a simple webook is required that will be contacted before the database is accessed. The authorization webhook can be set with the HASURA_GRAPHQL_AUTH_HOOK environment variable.
The above express route will read the x-uid header coming directly from the user and pass it on as X-Hasura-User-Id which can later be used to filter access.
The last option to add custom logic is with Events that will be triggered when certain operations are executed on a table. So for example you could run a cleanup job each time a user is removed from the users table to remove the assiciated media stored elsewhere.